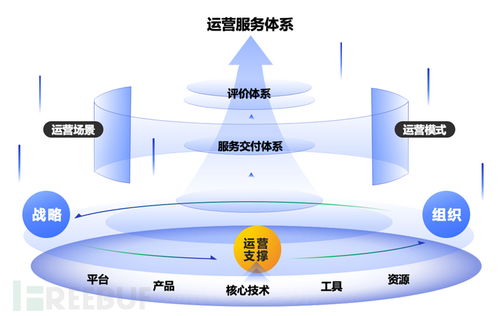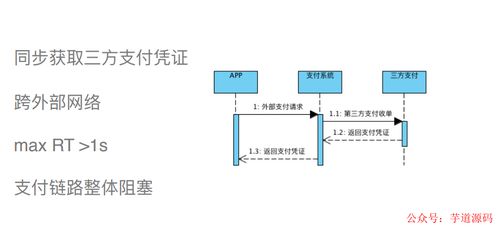
在消费金融行业飞速发展的浪潮中,我曾有幸深度参与一个核心业务系统的开发与全生命周期维护。那段交织着代码、故障与成长的岁月,不仅是一场技术的淬炼,更是一次对信息系统运行维护服务本质的深刻理解。
从蓝图到现实:开发期的远见与伏笔
项目启动之初,团队激情澎湃,专注于功能实现、性能指标和上线 Deadline。我们采用了微服务架构,力求高内聚、低耦合,为未来的可扩展性打下基础。年轻的团队难免更关注“建造”而非“养护”。一些为了快速上线而采取的临时方案,比如硬编码的配置、不够完善的日志记录、以及某些非核心流程的异常处理空白,都像一颗颗“技术债”的种子被埋下。当时我们以为,系统成功上线即是终点,殊不知,那仅仅是运维长征的起点。
上线日:兴奋与忐忑的序章
当系统经过多轮测试,终于在凌晨割接上线时,指挥中心里弥漫着咖啡因和紧张的气息。最初的几个小时风平浪静,大家松了一口气。但很快,真正的考验接踵而至。一个未曾预料到的用户并发场景触发了某个服务的线程池耗尽,导致部分交易超时。监控告警骤然响起,那是运维服务交响曲的第一个强音。我们被迫直面第一个教训:开发环境无法完全模拟生产环境的复杂性与不确定性。快速定位、预案执行、热修复代码、回滚……那一夜,我们完成了从开发者到运维者的初次角色转换。
常态运维:在平淡与风暴间行走
系统进入平稳运行期后,日常运维成为主题。这包括了每日的健康检查、性能指标监控(如API响应时间、数据库连接数、JVM内存使用率)、日志巡检以及定期备份。我们建立了知识库,记录每一次故障的处理过程,形成了宝贵的“运维剧本”。自动化脚本开始大量应用,从日志清理到批量数据修复,将运维人员从重复劳动中解放出来。“平淡”总是短暂的。一次第三方支付通道的异常波动,一次数据库的慢查询累积,甚至一次不经意的配置误操作,都可能瞬间将我们拉入“风暴”中心。印象最深的是某次促销活动,凌晨突然出现的数据库死锁,导致核心交易链路阻塞。那一刻,监控大屏上飙升的失败率曲线触目惊心。团队依靠清晰的链路追踪和事前准备的熔断降级策略,在15分钟内隔离了问题服务,启用了备用流程,避免了更大的业务损失。这次事件让我们深刻认识到,运维的核心价值不仅是“修复”,更是“预防”和“快速止血”。
演进与优化:系统与人的共同成长
随着业务量几何级增长,早期的架构开始显现瓶颈。运行维护服务不再是简单的“保稳定”,更需要驱动系统的演进。我们启动了数轮重要的优化:引入更精细化的链路监控和APM工具,实现了从用户端到后端服务的全链路可观测性;重构了部分核心服务的数据库访问层,引入缓存和读写分离,性能提升了一个数量级;建立了混沌工程实践,主动注入故障以验证系统的韧性。这个过程,也是团队能力的蜕变。运维人员从被动的“救火队员”,成长为能深入代码、参与架构评审、设计高可用方案的工程师。开发与运维的界限在DevOps文化下逐渐模糊,双方在共享的on-call轮值中增进了理解,共同为系统的SLA负责。
反思:何为卓越的运行维护服务?
回顾这段历程,我认识到,信息系统的运行维护服务绝非技术支持的配角,而是保障业务连续性的基石,是驱动系统持续进化的核心引擎。它要求我们:
- 具备前瞻性:在开发阶段就考虑可运维性,做好日志、监控、告警的埋点。
- 拥抱自动化:将一切重复、规范的流程自动化,提升效率,减少人为失误。
- 建立韧性思维:承认故障必然会发生,设计容错、降级、快速恢复的机制,而非追求不切实际的“零故障”。
- 持续学习与改进:每一次事件都是改进系统、流程和团队能力的宝贵机会。
那段与消费金融系统共舞的岁月,充满了深夜的报警、紧急的会议、成功的修复和失败的反思。它让我明白,一行行安静的代码背后,需要一个永不眠的、不断进化的运维服务体系来赋予其生命力和价值。这不仅仅是一份技术工作,更是一份对业务、对用户始终在线的承诺。